

Nowadays, almost every business experts understands the value of raw text and interested in Data Mining this type of data to predict the future, control the cost incurred and discover meaningful insights to the business. Research says, almost 80% of the business data are in the form of text. For example, online reviews, surveys, transcripts of call center, etc. Now, here’s a question arises, that how do we analyse these Textual data analysis to build the business standard? Text mining or text mining analytics serves the purpose. Text mining convert the textual data into a structured format to yield business conclusions. In this blog, I will brief you the most often used data sources for text mining especially in the financial sector.
The central aim of text mining is that analysing the text document by extracting the data from different sources like emails, reviews, official files, web pages, etc., and convert or transform them into suitable format for analysis to make better decisions. Text mining involves Statistical analysis and machine learning techniques for visualising and analysing the structured data. The most difficult part of any text mining is that to organise the data into structured form. In other words, the aim of text mining is to extract the knowledge or pattern from different text documents.
As I mentioned earlier, text mining transforms the unstructured text data to structured form and it has been increasingly valuable to the financial sector. The widely used data source for text mining are social media, emails, messages, forums and news articles. Some researcher use the documents like PDF and excel files for the data source.

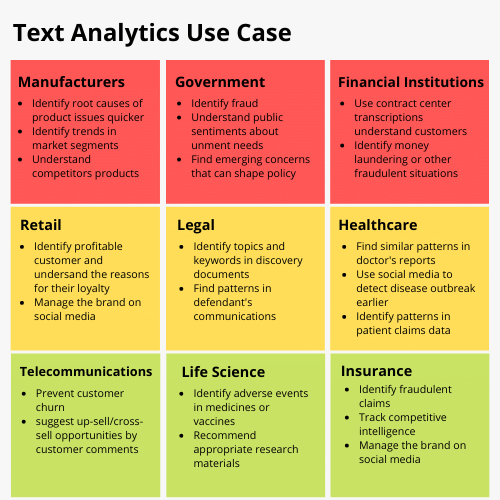
Figure 1 Text Analytics Use Cases
Normally, the financial sector produce a huge amount of internal data or unstructured data such as transaction data, customer data, etc., which helps them to take proper decisions. However, most of the decisions are taken along with the data collected from the external sources such as websites, social media. Turner, Schroeck, and Shockley, (2013) mentioned that about 71% of financial sectors use Big data analytics for developing their organizations. Thus, financial sectors adopts the big data technologies to store a wide source of textual data and from that, it can be analysed for the business needs. In this era, most of the financial sectors collects the textual data through internet and social media.Connect (2018) explained the top ten techniques in the artificial intelligence for analysing the textual Data analysis in financial industries. Nassirtoussi, Aghabozorgi, Wah, and Ngo, (2014) discussed the application of text mining in predicting the stocks in marketing sector with the data collected from social media and news articles.
When it comes to financial sectors, there are two basic data sources for text mining. They are internal data source and external data source. Internal data sources are transaction data, application data and log data. External data source is that data from social media and websites. Further, Zhang and Zhou, (2004) suggested that social media is the good source of data to be collected than any other source especially in the financial sector.
The most common method of Data collection is by using external data sources as they are free to use and user-friendly. However, the internal data requires the ownership and contains numerous restrictions as one can see in the fraud detection because many organisation often do not reveal the full information for fraud detection. The classification problems like model optimization, detection method of fraud, feature selection are the challenges faced by the researchers in the area of fraud detection. In addition, the only field where the internal data source is useful while dealing with legal documents. Numerous research use the internal data source such as financial statements, emails, reports, etc for improving the human resource management, for internal audit and customer management.
Further, recently, the biggest source for financial sector is the named entity recognitions. It allows the industry to extract the client information such as name, back account numbers, clients accounts in any social networks, etc. Ritter, Clark, and Etzioni, (2011) discussed that even with the named entity data collection, there are often noise present in the data while we adopt the supervised techniques of mining (Narayanan & Jaiswal, 2018). Apart from the named entities, forums are the helpful data source for collecting textual data in the financial world and a time series model is the best explained model for this type of data.
In conclusion, there are abundant text data and it turns out to be the dominant source in the business domain. The text data are mostly unstructured in nature and mining these data leads to the structured form. There are several research studied that the text mining is used to analyse the vast amount of data collected from different platforms like social media, newspapers, and this incorporates traditional internal data sources to develop the business standards. Text analytics can be performed by using different statistical and machine learning concepts to improve the financial sectors. The data in the financial sectors are often collected from corporate documents, text from social networks, opinions of customers, emails, etc. Text mining aims to identify the innovative decisions to business like answering where, when, why, and how. Thus, from this blog, one may understand that there are huge amount of textual data available nowadays, it is often important to devise a proper target to achieve the goal. Further, in recent times, most financial organisations use the external data source to increase the revenue and customize their business. A good example is that people purchasing a product from a shopping website. The company analyse how often they view their product and from the reviews of the product they take further decisions to improve the quality of the product. Thus, in general, external data source is the most often used data source for text mining in financial sector.
References
- Narayanan, S., & Jaiswal, S. (2018). Connecting the Banking World. Artificial Intelligence Powered Banking (Vol. 10). Retrieved from https://active.ai/wp-content/uploads/2018/05/Finacle-Connect-2018-leading-ai-online.pdf
- Nassirtoussi, A. K., Aghabozorgi, S., Wah, T. Y., & Ngo, D. C. L. (2014). Text mining for market prediction: A systematic review. Expert Systems with Applications, 41(16), 7653–7670. Retrieved from https://www.sciencedirect.com/science/article/pii/S0957417414003455
- Ritter, A., Clark, S., & Etzioni, O. (2011). Named entity recognition in tweets: an experimental study. Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, 1524–1534. Retrieved from https://www.aclweb.org/anthology/D11-1141.pdf
- Turner, D., Schroeck, M., & Shockley, R. (2013). Analytics: The real-world use of big data in financial services. IBM Global Business Services, 27. Retrieved from https://www.mdpi.com/2071-1050/11/5/1277/pdf
- Zhang, D., & Zhou, L. (2004). Discovering golden nuggets: data mining in financial application. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 34(4), 513–522. Retrieved from https://ieeexplore.ieee.org/abstract/document/1347303/