


Genomics and bioinformatics: analysis of several large genetic datasets such as the 100,000 genomes project and the uk bio bank.
March 25, 2020
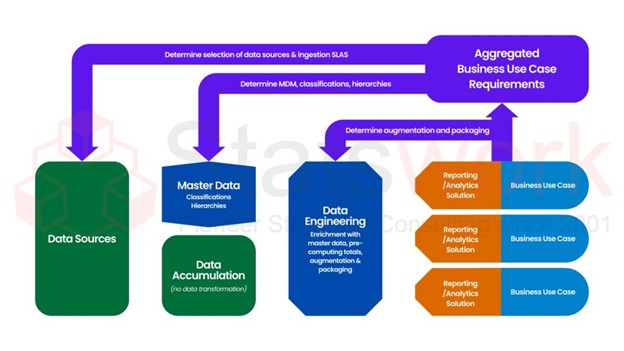
Intelligent data analysis and visualization
April 10, 2020Formulate statistical models (linear regression; logistic regression; factor analysis) using data from extensive social surveys.
Meta Analysis Service
Recommended Reads
Contact us
Formulate statistical models (linear regression; logistic regression; factor analysis) using data from extensive social surveys.
Model building is a robust and challenging skill in Statistical Analysis as in every step we have to examine the model and make a decision for the next level. If only predictive models are used, and relationship among variables are not necessary, it is much more comfortable, in this case, we can run a simple stepwise regression model which will give the best results. If we need to find the relationship and describe variables, then we need to find some appropriate tests, we can’t use theory always in the practical situation as it has its difficulty. If we have ten different variables, we can measure it in many different ways (Becker, 1998) .
Some guidelines to be kept in mind:
- The regression coefficient is marginal results: that is coefficient for each predictor is a unique effect than the predictors on the response. Unless all the predictors are independent of each other, the fact is not complete, so we should know what else is in the model as a model may change depending on what is there in the model.
- Start with univariate descriptive and graphs: It’s a prime step, its always necessary to start with Descriptive Statistics. It helps us to find errors, and we can easily see what’s happening in data. The first step of analysis is to find the univariate descriptive and graphs, which help us find the better breaks in the middle of the distribution, the variation in the data etc. Generally, if the person is not having an idea about his data and if it is directly used for modelling, we can’t reason out for the unusual behaviour of the same. But the descriptive is found then we can definitely do better modelling with better understanding (Deville, 1993).
- Run bivariate descriptive including graphs: We need to know how predictors are related to each other and how well it relates to the outcome variable. As the Regression Coefficient is marginal results, we know when we start the regression model in each step, we will lose the significance of some variable in a bigger model. What most of the researcher suggest is to always find the scatter plot apart from correlation and crosstabs, as we get to know the clear-cut image if we need to deal with nonlinearity in some way.
- Analyse predictors in sets: always the model that we design should be meaningful, overlapping of predictors are not good, and independent variables should always be independent of each other and should be an effective risk factor of the dependent variable. If there are subsets in an independent variable, it will be difficult to access as there will be a correlation between the variables in the subset, but across the subset, there will not be much of correlation. By building each set separately first, you can build theoretically meaningful models with a solid understanding of how the pieces fit together (H Lu, 2003).
- Model building and interpreting will be done parallel: Every model in each step tells us result so in every step we need to stop and analyses properly. We need to check coefficient, R-squared, if there are any changes, how much do coefficients change from a model with control variables to one without, if we look into this, we can make a better decision.
- Any variable involved in an interaction must be in the model: Its usually good to remove the non-significant variable from each step from the model, but the question is are they important to the research question or not. Sometimes we put all the variables in the model and check for significance; in some case, the variables that one excepts not to be significant will appear not to be significant. The interpretation of interaction is only possible if the component term is in the model.
- The research question is essential: Most of the time if the research question is really well progressed and a large set of variables are collected which equally contributes to the research question that means a larger set of Data Collection, then its very hard to finish of the modelling as we will be involved in testing all the variables, every possible predictor that is categorized. But we have diverted from the real target. Its always good to make a point very clear, that what is the target, i.e. what is the main objective and aim that must be proved so that it will be easy for a person even though the data set is huge. All these guidelines must be followed for all type of modelling that can be ANOVA, linear, logistic, multiple linear regressions.
Simple Linear Regression
The concept of Linear Regression is mainly used to describe how one variable can be used to predict another, i.e. how clearly the independent variables (predictors) can predict the outcome that is an event of interest, linear regression is also a type of model fitting. A linear regression model consists of two parts: the equation for the best fitting model and the error term representing the variation around the linear trend. The model of simple linear regression is as follows:
Yi= α + βxi + ei
Where Yi is the outcome, variable and xi is the value of the predictor for the ith individual whereas alpha and beta represent the parameters, i.e. quantities to be estimated in the model. The intercept (alpha) represents the average value of the predictor is 0. Beta is equivalent to the slope of the line; represent average change in the outcome per one unit increase in the predictors. In a practical scenario, when the dependent variable (outcome) variable is continuous, we can apply simple linear regression for those data sets, independent variables can be both categorical and continuous.
Assumptions
While fitting a linear regression model, we have an assumption that the relationship between Y and X is linear, as X increases Y increases or decreases in a straight line pattern, we can check this basically before any analysis using the scatter plot.
When we use our model to make inference about the population, we have few assumptions in addition
- The observations are independent of each othero
- The errors have a constant variance
- The values of the outcome Y follow a normal distribution for each value of the predictors.
Logistic Regression
In simple linear regression, the outcome variables should always be always continuous; we cannot use a binary categorical outcome. Hence we use an extended version of linear regression, i.e. Logistic Regression wherein the outcome variable is binary, for example, alive/death or yes/no kind of outcomes are allowed. And the independent variables or predictors can be both categorical and continuous. Interpretation is slightly different from linear regression here we interpret in terms of odds. If the event of interest (outcome) is not binary, we have ordered we set of variables as a dependent variable for example severity of the disease is mild, moderate and severe in such case one has to use ordinal regression. If the dependent variables are more than one, then we go about with Multiple Linear Regression.
Factor Analysis
In this method, maximum variance from all the variables is taken, and it is represented as a common score which can be used for future analysis. Factor Analysis is widely used in psychometrics, operation research, biology, finance etc. The basic purpose of this method is data reduction, and it helps in representing the correlation among multiple outcomes. It’s a very powerful technique that makes the researchers investigate concepts that are very difficult to analyse.
There are two types of factor analysis:
- Exploratory Factor Analysis
- Confirmatory Factor Analysis
References
- Becker, D. E. (1998). The New York City Social Indicators Survey: An analysis of the weighting procedure.
- Deville, J.-C. (1993). Deville, Jean-Claude (Vol. 88). Taylor & Francis Group.
- H Lu, A. G. (2003). LU, H. and GELMAN, A. (2003). A method for estimating design-based sampling variances for surveys with weighting, poststratification and raking. J. Official Statistics 19 133–151. Journal of Official Statistics.


