

Multiplicity Problem in Clinical Trials and Some Statistical Approaches
In most of the clinical trial problem, researchers often face multiple testing problems that have an impact on type I and type II error rates, results in invalid inference. Thus, the multiplicity issue should be considered at the beginning stage i.e. starting from the design, Data Analysis and Interpretation of the study.
What is multiplicity?
Inflation of type I error rate from a Multiple Testing problem is commonly referred as multiplicity. Type I error is simply the error rate when rejecting the null hypothesis when it is true and it is referred as significance level of the trial. If there exists the problem of multiplicity, then it should be adjusted in the testing problem. .
Why do we need to consider multiple testing adjustments?
Suppose a set of hypotheses are tested within the same study simultaneously, then the probability of rejecting at least one null hypothesis (i.e) type I error rate is increased, thereby results in a high risk of finding false positive. .
For example, consider a study of five independent null hypotheses, and each are tested simultaneously at 5% level of significance, and the result from the test is that the overall type I error rate is 23%. However, probability of atleast one significant result will be calculated using 1−(1−α)k; where k is the number of tests. In such situation, adjustments in multiple testing problem is needed otherwise it yield invalid result that 23% chance to get atleast one significant result when the null hypothesis is actually true but we assume that the error rate is maintained at 5% level. Also, the false positive findings depends on the sample size of the study. Thus, multiplicity adjustment should be necessary in designing, Data Analysis and interpreting the results..

Here is the list of common questions emerges when one think of multiplicity issue: I do not explain each one of them in this blog, if you wish to know the answers to the following questions please read the paper by Li et al (2017).
- When should we consider multiplicity adjustments?
- Is the trial of exploratory or confirmatory nature?
- Are the treatments distinct or related?
- Are findings summarized in one conclusion?
- What if there are multiple outcomes?
- What if we have repeated measurements for the same outcomes?
- What if we have multiple secondary outcomes?
- What if we run multiple subgroup analyses for the same outcomes?
- What if we conduct multiple sensitivity analyses for the same outcomes?
- What if we want to conduct multiple secondary analyses using the trial data to answer other research questions ?


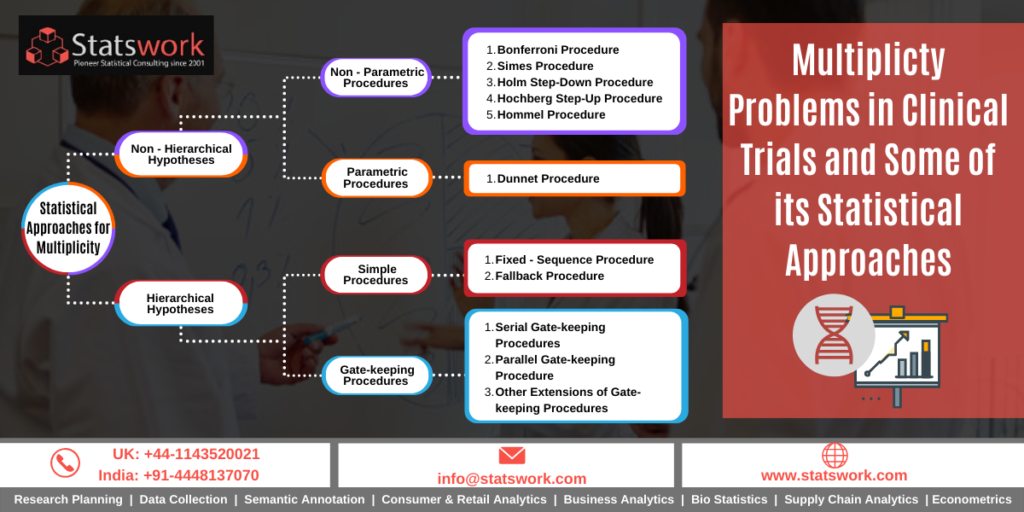
Statistical approaches for multiplicity
Several Statistical Methods have been proposed by many researches for handling the multiplicity testing problem. The most common and simple method is the Bonferroni adjustment based on the P-value. Here, the individual comparison are tested at specified significant level. Usually, significant level is considered as A/K where A is the experiment error rate and K is the number of comparisons. One demerits of this adjustment is that it yields low power with irrelevant null hypothesis. Later, Bonferroni approaches have been modified by Holm and Hochberg and this method is still popular for handling multiplicity problems.
There are different methods available in literature to handle the multiplicity testing problem. Recently Wang et al (2015) listed out some of the multiple testing problems in clinical trials. Here is the gist of procedures reviewed in that paper.

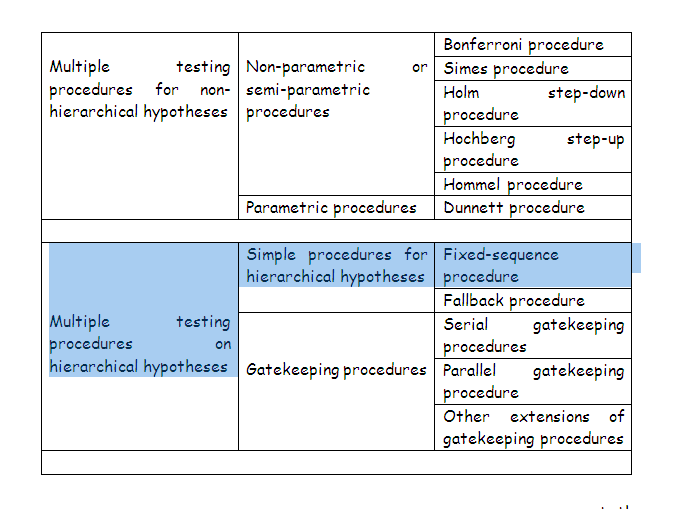
Suppose, if there is a prior evidence about the test is more significant, then Dunnett or stepdown Dunnett procedure is used for the multiplicity adjustment. And, if suppose, the study have different types of tests and different endpoints, then the gatekeeping method is used for the adjustment.
Multiplicity Adjustments: Gatekeeping, fixed-sequence, and fallback procedures
Let us understand the differences among the different multiplicity procedures that are useful in the clinical trials:
Gatekeeping Procedure is used in the situation when there are multiple endpoints and are grouped into different families.
Fixed Sequence Procedureis a stepwise multiple testing procedure that is constructed using a pre-specified sequence of hypotheses. The advantage and disadvantage of this testing procedure are obvious: power will be maximized as long as previous hypotheses are rejected, but minimized if a previous hypothesis is not rejected. Another drawback for this procedure is that the ordering of multiple hypotheses based on the clinical importance is subjective in nature..
The Fallback Procedure: is similar to a fixed sequence test, in which hypotheses are tested in an a priori order at the full alpha level. The difference of the fallback procedure from the fixed sequence test is that the full alpha of 0.05 is split for endpoints in a pre-specified order and the hypotheses in late order can still be tested (but with different alpha levels) if the previous hypothesis is not rejected. .
In conclusion, multiplicity problem is not uncommon in the clinical trials if we have one or more treatment in the study. Thus, more appropriate statistical methods is necessary to deal with the multiplicity problem which reduces the false positive findings under the assumed null hypothesis
References
- Chow SC. Controversial Issues in Clinical Trials. New York: Chapman and Hall/CRC Press, Taylor & Francis; 2011.
- Guowei Li, Monica Taljaard, Edwin R Van den Heuvel, Mitchell AH Levine, Deborah J Cook, George A Wells, Philip J Devereaux, Lehana Thabane. An introduction to multiplicity issues in clinical trials: the what, why, when and how. International Journal of Epidemiology, Volume 46, Issue 2, April 2017, Pages 746–755