

Brief:
- Data science and biology is a program that combines to form a domain-specific knowledge of science and engineering.
- Statistical Data Analysis services provide genomics to clinical records, from imaging to mobile.
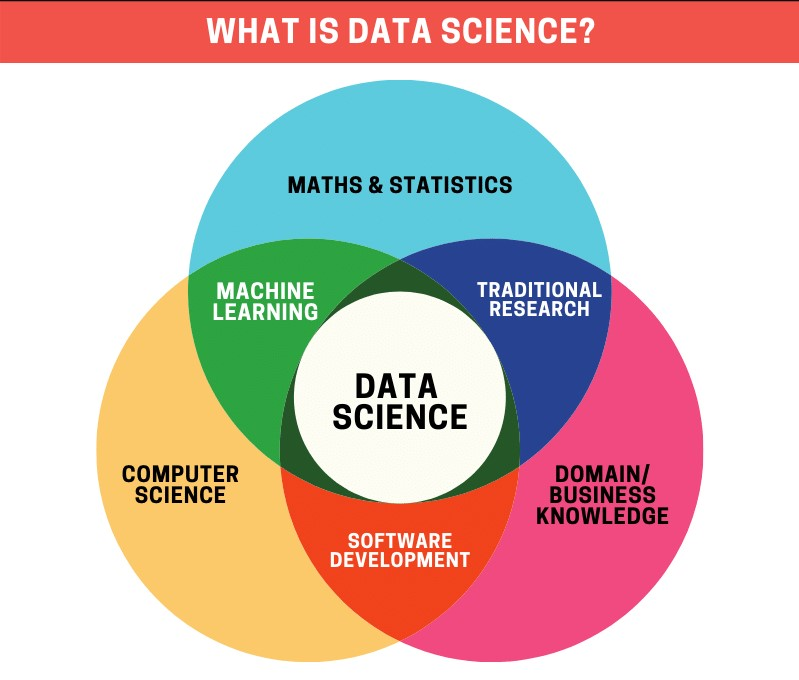
- Data science is a field that utilizes the scientific methods, their processes, algorithms and hypothesis to from many structured and unstructured data.
Data science is closely related to Data mining and big data. It is a concept that combines statistics and data analysis with their related method to understand the actual phenomena. Statistical techniques are data-driven and allow you to perform operations on the data so that we can gather insights from the data.SPSS Data Analysis provides full assistance in your qualitative and qualitative analysis
Purpose of statistical learning:
- It is essential to learn the basic ideas behind the various techniques, To know how and when to use them. Statistical analysis services experts utilize a unique method in a combination of inferences based on collected data and population understanding used to predict information in an idealized form.
- Quantitative Statistical Analysis help you get a visual representation of data based on research that has collected.
- Statistical Analysis of Qualitative Data statistician assists you with a statistical model to make a representation of the data.Toanalyze to infer any relationships between variables.
- Professional Help with Analysis of Statistical Data assists in deriving valuable insights from data, which is emerging to meet the challenges of processing massive datasets.
- A data science view provides practitioners with process and principles, which give the data scientist a hypothesis to solve problems by extracting useful knowledge from data systematically.

Computational and Statistical Models for biological data:
This method study design that allows geneticists to more fully exploit these new laboratory methods to study complex traitsin humans. SPSS Statistics help and data analysis services can help you in data miningto produce results with accuracy. The methods developed here will lead directly to improve understandingof the molecular basis of many human characteristics and diseases – an essential step inthe path towards new treatments and therapies. In recent years, Computational andStatistical Models for Human Genetics play an important role.Secondary Qualitative Data Analysis can assist you in selecting the best research design for your context.
Statistical Techniquesfor working extensive biological data:
Linear Regression:
This method used to study the target variable, which works by mapping a linear relationship between two variables.—classified into two types simple linear and multiple linear regression. Simple Linear Regression is a single independent variable to predict a dependent variable by fitting thelinear relationship. It achieves the best fit by reducing the sum of all the distances between the shape and the actual observations.Statistical analysis and consulting servicesexperts team trained to provide, data processing, and data preparation and planning for statistical development.
Classification:
It is a technique of data mining which allows a category to a collection of data for better analysis and reliable predictions. Now if a new observation comes, the classification will be able to determine and assign a variety to a recentstatement. Also sometimes called a Decision Tree, it is one of several methods intended to make the analysis of massive datasets effective.
Resampling Methods:
Resampling is the method that uses samples from the original data. It doesn’t utilize generic distribution tables to calculate approximate values of probability.Resampling generates a unique sampling distribution based on the actual data. It has application in experimental methods, rather than analytical methods, to develop the unique sampling distribution. To learn the concept of resampling, you should understand the terms Cross-Validation and also boot stamping.
Support vector machine:
It is a machine learning algorithm. Professional help with statistical analysis helps in solving classification and regression problems. In SVM, each data item defined as a point in n-dimensional space. After the plotting is over, classification is performed to find a hyper-plane that which differentiates two classes.
References:
- McCullagh, P. (2002). What is a statistical model?. Annals of Statistics, 1225-1267.
- Tang, Q. Y., & Zhang, C. X. (2013). Data Processing System (DPS) software with experimental design, statistical analysis and data mining developed for use in entomological research. Insect Science, 20(2), 254-260.
- Pal, P., Mukherjee, T., & Nath, A. (2015). Challenges in Data Science: A Comprehensive Study on Application and Future Trends. International Journal in Advance Research in Computer Science and Management Studies, 3(8).