

What is Data science?
We are in the age of big data. The frameworks like Hadoop have managed to solve the problem of data storage. Data Science is defined as a combination of various tools, algorithms, and machine learning principles to understand, analyze and process raw data to provide insights that can help organizations make informed decisions.
Data science created quite a buzz among the tech-enthusiasts, especially after being deemed ‘the sexiest job of the 21st century’ by the Harvard business review. It is a systematic and scientific approach to gaining valuable insights from the deluge of data that began with the proliferation of smart devices and the internet of things. Data science is often closely associated with the concepts of data mining and big data analytics; while the former is a broader term representing systematic processes involved in the knowledge extraction from any data, the latter two are specific processes involved in analysing data, especially big data.
Before the era of big data, most of the data were small and could easily be analyzed with the help of BI tools. Data was also well structured. According to projections from the IDC, 80% of all data will be unstructured by 2020. Unstructured data makes it challenging for organizations to use the information for searching, analyzing, and editing.
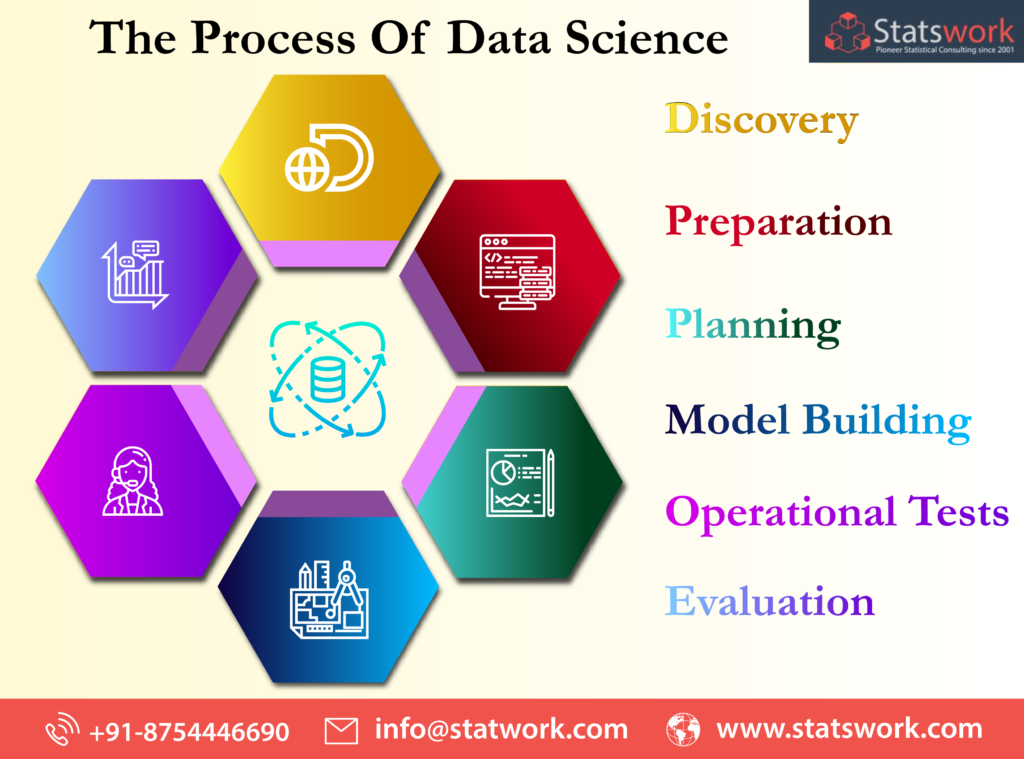
Data science is a systematic process, and the following are the main phases of Data Science:
Discovery:
Before initialization, it is necessary to let the data scientists know what are we looking for, all the various specifications, requirements, priorities along with the required budget. Here, the data scientists frame the business problem and formulate initial hypothesis with raw data.
Preparation:
Data scientists perform analytics for the entire duration of the project. They explore, understand, assimilate and condition data before modelling. Then, they collect and transform all this data to understand the outliers and relationship between variables.
Planning:
Next, Data scientists determine methods and techniques to draw the relationships between variables. These relationships will set the base for the algorithms which will help predict future trends.
Model building:
In this phase, the scientists develop datasets for training and testing purposes. They utilize various learning techniques like classification, association and clustering to build the model and test the predictions it offers, and the truth in them, if it is consistent with past results.
Operational tests:
In the penultimate phase, the data scientists deliver final reports, briefings, code and technical documents. They may also recommend the company implement the hence created project in a real-time production environment. This small-scale testing will help end minor problems which may have cropped up while serving as additional proof of the project’s accountability.
Evaluation:
A data scientist’s job does not end with the implementation of the project. Post Implementation, data scientists have to collect new data, evaluate and supply information to the company.
Data science makes it possible to train models to infer from unstructured data. It is mostly used for decision making, restrictive analysis, and predictive casual analysis. Some of the practical applications of data science include,
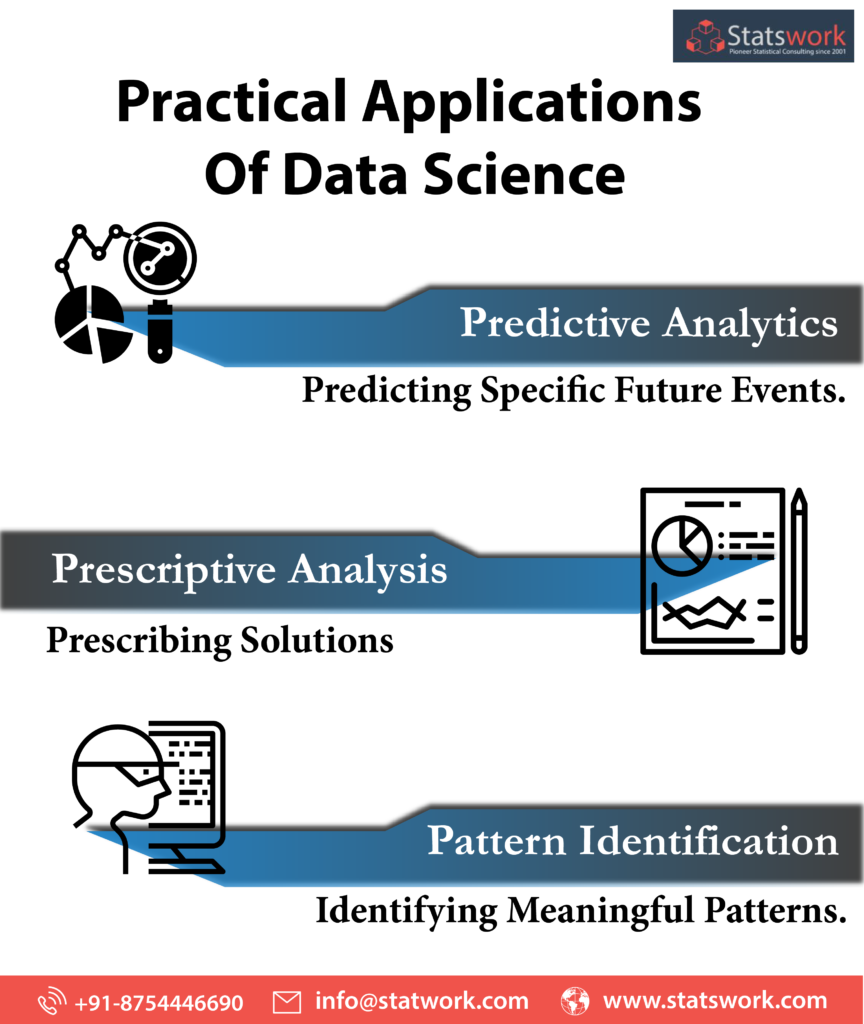
Predictive Analytics:
Data Science makes it possible for enterprise owners to predict specific future events. For example, banks use big data containing customer information to analyze the likeliness of customers making future payments in time.
Prescriptive Analysis:
Data science cannot only be used to predict events based on given parameters, but also prescribe solutions. One of the best examples of prescriptive analysis is self-driving cars. With the help of data science, the vehicles are capable of making decisions on behalf of the driver for making turns or adjusting speeds.
Pattern Identification:
Data science can identify meaningful patterns. Clustering is the most commonly used method for pattern discovery. A great example is the implementation of data science to discover target markets for retail outlets based on the traits of potential customers.
Links, References, Related Posts:
–Learn Data Mining Concepts And Techniques Via Programming Languages
–Top 9 Life Hacks To Simplify Data Analysis
–Simple Data Analysis Techniques, Top 5
–Approaching Data Analysis: How To Interpret Data? – Beginners Guide
 Next Post
Next Post